 Grégory TAUDIN - 8 juin 2022
Grégory TAUDIN - 8 juin 2022NestJS : L'approche Code First avec TypeOrm

Nous allons utiliser dans ce projet une approche dite « code first ». C'est-à-dire que nous allons créer des classes pour définir notre modèle de données (les entités) et ensuite un outil viendra les convertir en tables. Cela nous permettra de requêter les données générées par l'intermédiaire de service de dépôts de données (repositories).
La librairie que nous allons utiliser est « TypeOrm », cette librairie OpenSource est totalement intégrée au sein de NestJS.
TypeORM est un ORM qui peut s'exécuter sur les plates-formes NodeJS, Browser, Cordova, PhoneGap, Ionic, React Native, NativeScript, Expo et Electron et peut être utilisé avec TypeScript et JavaScript (ES5, ES6, ES7, ES8). Son objectif est de toujours prendre en charge les dernières fonctionnalités JavaScript et de fournir des fonctionnalités supplémentaires qui vous aident à développer tout type d'application utilisant des bases de données, des petites applications avec quelques tables aux applications d'entreprise à grande échelle avec plusieurs bases de données.
TypeORM prend en charge les modèles Active Record et Data Mapper, contrairement à tous les autres ORM JavaScript actuellement existants, ce qui signifie que vous pouvez écrire des applications de haute qualité, faiblement couplées, évolutives et maintenables de la manière la plus productive.
TypeORM est fortement influencé par d'autres ORM, tels que Hibernate, Doctrine et Entity Framework.
Installation
A la racine du projet, ouvrons un terminal et lançons la commande suivante :
> npm i -g typeormEnsuite nous avons besoin d'utiliser la couche NestJS pour TypeOrm et SQLite 3 :
> npm i @nestjs/typeorm
> npm i typeorm
> npm i sqlite3Pour la configuration de TypeOrm, il faut rajouter un fichier de configuration à la racine du projet : ormconfig.ts
Nous utilisons la connexion SQLite et fournissons quelques informations :
- type : SQLite
- database : nom de la base de données (du NodeJS .env)entités : le chemin des classes d'entités.
- synchronize : synchroniser toutes les mises à jour des entités à partir du code directement dans la base de données.
- migrations : le chemin des fichiers de migration. Cette approche est recommandée pour la production. Chaque fois que vous mettez à jour les classes d'entités, vous devez utiliser une commande pour créer des fichiers de migration. Ils contiennent toutes les informations dont TypeOrm a besoin pour mettre à jour la structure de la base de données ainsi que le script de restauration si le processus de mise à jour de la base de données échoue. Lors d'une mise en production, TypeOrm applique chaque fichier de migration pour mettre à jour la base de données et ainsi garde une trace de toutes les opérations qui ont été faites sur celle-ci dans une table « migrations ».
A l'intérieur de la librairie, créons un dossier « entities » pour définir nos entités :
Notre API retournera des items d'un inventaire de jeux :
Cette classe possède 4 propriétés :
- un ID,
- un nom,
- une description,
- un niveau de puissance.
Remarquez les décorateurs TypeOrm qui permettent de décrire les propriétés et donc nos futures colonnes :
- @Entity permet de définir des propriétés sur la future table. Là, en l'occurrence, le nom de la table.
- @PrimaryGeneratedColumn() permet de définir un Id auto généré.
- @Column() permet de spécifier si la propriété est une colonne.
Maintenant nous allons configurer TypeOrm par l'intermédiaire de l'import de module. Dans le fichier « shared.module.ts » rajoutez les lignes suivantes dans le décorateur @Module :
Nous spécifions ici que nous utilisons une base de données de type SQLite et que nous allons avoir besoin de requêter les objets de type : « InventoryItem ».
La structure de notre inventaire est prête, nous avons besoin de créer un service pour exploiter ces nouvelles données.
A la racine, ouvrons un terminal et lançons la commande suivante :
> nest generate service services/inventory
? Which project would you like to generate to?: Shared.La CLI va créer pour vous deux fichiers, un pour le service et l'autre pour les futurs tests unitaires.
Nous pouvons implémenter notre première logique de lecture de données :
Remarquez l'injection de dépendance sur le dépôt de données « TypeOrm » au travers du constructeur. Notre première méthode « findAll » est très simple et retourne un tableau de « InventoryItem ».
Rajoutons dans notre build la librarie :
"build:shared": "nest build shared",Ainsi, nous pouvons construire notre librairie à la demande.
Enfin, nous avons besoin d'exposer le service au travers du module de la librairie. Allons dans le dossier "apps/reader/src/reader.controller.ts" et mettons à jour le code:
Nous injectons dynamiquement le service au travers du constructeur, nous créons une nouvelle méthode « findAll » de type GET et finalement nous appelons notre service.
Il est temps de tester le résultat ! Depuis un terminal, lançons la commande suivante :
> npm run start:readerNous utilisons POSTMAN pour les tests :
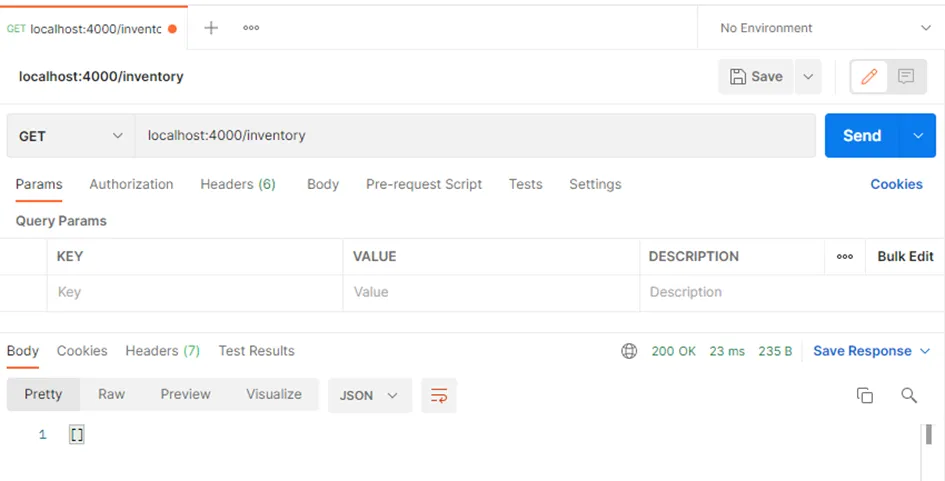
Appel de la méthode FindAll
Notez que lors du lancement de la solution, TypeOrm a généré la base de données dans :
> db/sqliteSi nous ouvrons la base SQLite avec DBeaver par exemple (c'est gratuit et fonctionnel), nous trouverons une base totalement en adéquation avec le modèle informatique que nous avons défini !
Nous pouvons maintenant remplir la base avec un exemple de données. Exécutons la requête SQL suivante dans la base :
INSERT INTO inventoryItem (name, description, powerlevel)VALUES('My First Item', 'The description of the first item', 1);et relançons notre API :
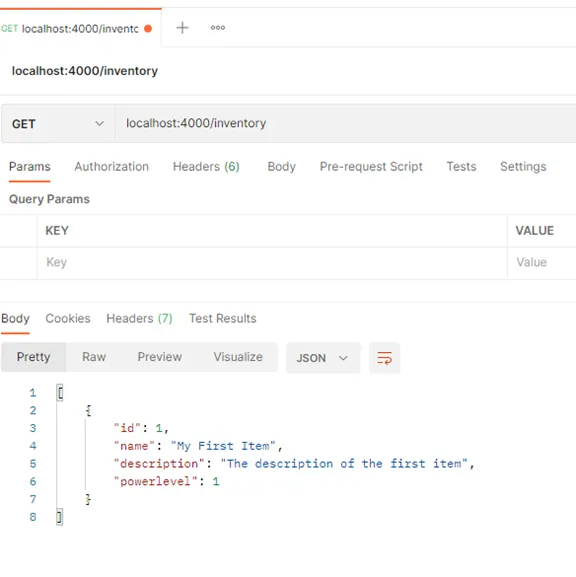
L'item est correctement remonté par l'API Reader !
Intéressons-nous maintenant à l'API Writer. On aimerait pouvoir ajouter des items d'inventaire depuis un appel de l'API. Il faut, dans un premier temps, modifier le service pour rajouter notre fonction de création.
Petit rappel des conventions REST pour les opérations de type C.R.U.D. :
- C : (create) => utilisation du verbe HTTP POST,
- R : (read) => utilisation du verbe HTTP GET,
- U : (update) => utilisation du verbe HTTP PUT,
- D : (delete) => utilisation du verbe HTTP DELETE
Modifions le contrôleur de notre application et rajoutons une fonction de type POST car nous allons créer une ressource de type « ItemInventory ».
La nouvelle fonction asynchrone « create » reçoit un item de type « InventoryItem » et l'enregistre en base grâce à l'appel du dépôt de données et de la fonction « save ».
Retournons dans le contrôleur et créons une nouvelle fonction de type @POST et appelons le service pour enregistrer l'item passé en paramètre. Notez le décorateur @Body qui permet de récupérer l'objet directement depuis le body du message entrant.
Nous utilisons les bons verbes HTTP pour les opérations C.R.U.D avec les décorateurs @Post(), @Put() et @Delete().
- Le décorateur @Body() permet d'obtenir directement depuis le body le contenu de la requête.
- Le décorateur @Param() permet d'obtenir les paramètres de la QueryString.
- ParseIntPipe est un PIPE NestJS prêt à l'emploi pour convertir le paramètre id de string en int.
Ouvrons le fichier "package.json" à la racine du projet et ajoutons la ligne ci-dessous dans la section "scripts" :
start:writer": "nest start writer --watch",Dans la section « scripts », ouvrons un nouveau terminal et tapons la commande que nous venons de saisir :
> npm run start:writerDans POSTMAN configurons notre requête comme ci-dessous :
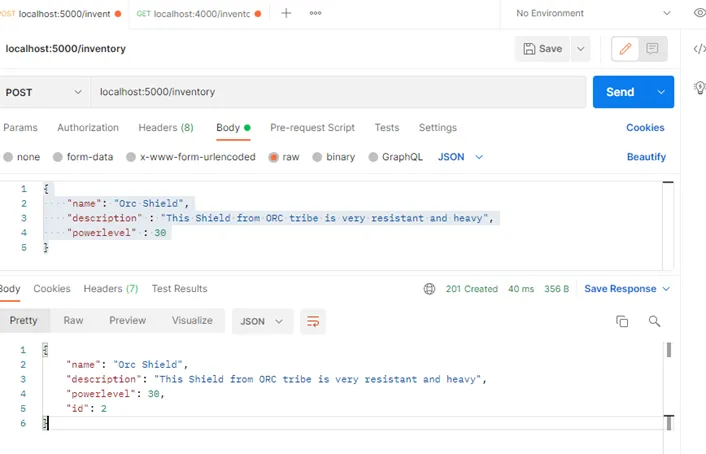
Le retour de l'API est un objet de type « InventoryItem » d'ID 2. L'objet est bien enregistré en base. Utilisons le Reader pour récupérer les nouvelles données et vérifier que tout est conforme :
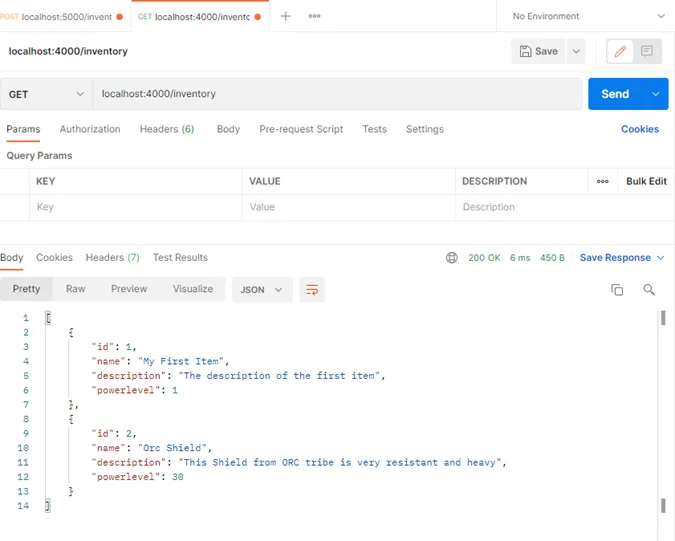
Le nouvel item apparaît dans la liste !
Mission accomplie !
Nos APIS C.R.U.D sont fonctionnelles, nous pouvons penser à la prochaine étape : Les tests : unitaires et E2E.